Reflection on "How not to structure your database-backed web applications: a study of performance bugs in the wild"
· 2887 words · 14 minutes read
The morning paper
I’ve been subscribed to the morning paper for over a year now. On it, the author Adrian Colyer, reviews and discusses a computer science research paper every single day. It’s a very impressive feat, considering the breadth of knowledge that is required to even understand the papers that he writes about. Furthermore, the fact that he’s managed to go non-stop without breaking this consistent rhythm since at least October of 2014 makes his efforts even more spectacular.Naturally, I can only recommend his blog if you want in touch with the latest in academic computer science.
My particular interests are geared towards Coyler’s posts involving programming language theory, formal methods, and topics… He reviewed such a paper last month entitled How not to structure your database-backed web applications: a study of performance bugs in the wild. It falls in the latter category because it talks about common performance issues in web applications caused by the use of Object Relational Mapping (ORM) frameworks. During the day, I am the CTO and sole engineer working on Sutori, a Rails-backed single-page application.
In the 5 years that we’ve been working on Sutori, I’ve come across my share of performance issues. Therefore, I thought it would be useful to complement my reflection of the research paper with my own experience.
The setup of the experiment
The ultimate goal of the paper is to shed light on the most common performance anti-patterns that are caused by the usage of an ORM framework with a particular focus on Ruby on Rails applications where the ORM is ActiveRecord.
Choice of applications
The authors picked 12 open-source Rails applications to analyze. The number of performance issues that they’ll end up finding is strongly correlated with the quality of the developers in the project. Therefore, I think that the applications that they selected for their analysis is important for the relevance of the findings. I know four of them: Discourse, Gitlab, Diaspora and Openstreetmap.
Of those, Gitlab is a big application with a fairly good reputation so it was a good choice to include it in the analysis. Discourse is also an interesting choice because one of its co-founders, Sam Saffron, is one of the leading experts in Ruby performance (just have a look at his blog). Assuming that he’s also one of the core developers on Discourse, we can imagine that the level of attention to performance in the code base must be high, and therefore the number of issues low compared to the other applications.
Simulating production data
After picking the applications, the authors must first identify particularly slow pages and actions. They are correctly observe that database-level performance issues only manifest themselves when there’s sufficient data. Things like N+1 queries and missing database indexes become visible only in production, not when you’re developing locally with your few records of seed data.
To solve this problem, the authors collected real-world statistics from each application based on its public website. They then synthesized database contents based on these statistics along with application-specific constraints.
Specifically, we implement a crawler that fills out forms on the application webpages hosted on our profiling servers with data automatically generated based on the data type constraints.
Which is a pretty neat way of setting up the experiment.
Categorizing the issues
The authors found several types of recurrent issues throughout the applications. Here, I select the ones that I have seen the most when working on Sutori.
Inefficient queries
The following two lines of code, although functionally equivalent, result in two different SQL queries where one is slightly less efficient.
# inefficient because of the unnecessary ordering
# SELECT * FROM users WHERE id = 1 ORDER BY id ASC LIMIT 1
User.where(id: 1).first
# efficient
# SELECT * FROM users WHERE id = 1 LIMIT 1
User.find_by(id: 1)
Moving computation to the DBMS
Oftentimes, one can move computations from the application directly to the database, resulting in faster execution. Indeed, for one the results from the database don’t have to be marshalled to Ruby objects. Secondly, operations in the database are highly optimized and are run as native code instead of being interpreted.
# inefficient
User.pluck(:total).sum
# efficient
User.sum(:total)
N+1 queries
N+1 queries are classic issues that have already been worn with discussion, but if you’re unfamiliar with them or want to brush up on the issues, you can learn more about them here. Below I talk about how we try to prevent them at Sutori.
Missing database indexes
The absence of an index on a column that requires one has a huge impact on the performance of SQL queries. This problem is not so much an issue anymore if you use the Rails migration generator as it automatically adds indexes on foreign keys (and foreign key constraints!). But it can still bite you if you perform queries based on a column that is not a foreign key.
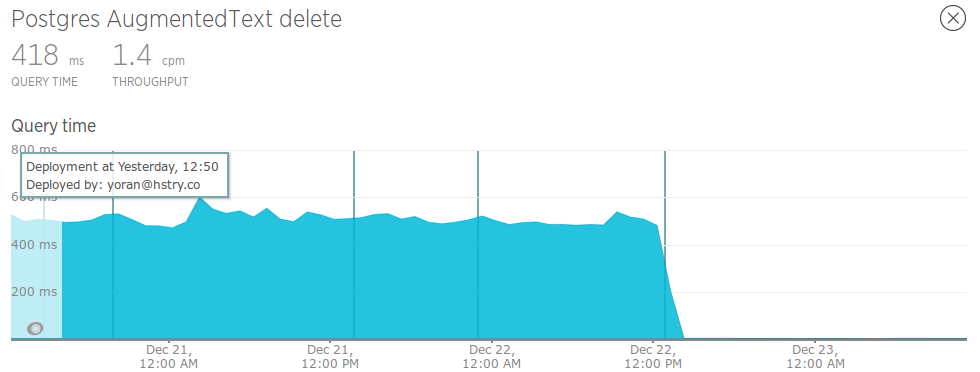
Fixing a missing database index issue is still one of the most gratifying performance fixes you can do.
Bonus: forgetting the use of OR
This issue did not appear in the findings of the paper. However, I would like to
include it here as it’s a persistent problem before Rails 5 introduced the or
method.
Imagine you have to do a union of multiple queries, as in:
users_with_a_subscription = User.where(is_subscribed: true)
users_from_the_eu = User.where(region: 'eu')
First solution: concatenation of arrays of records
You could try the inefficient way.
users_with_a_subscription = User.where(is_subscribed: true)
users_from_the_eu = User.where(region: 'eu')
result = users_with_a_subscription + users_from_the_eu
There are two problems here:
- You perform two SQL queries.
- More importantly, it converts the result of both queries into Ruby arrays,
which loads all the records into memory. Remember the rationale for the
existence of
find_eachas opposed toeach? If you have 100,000 users with a subscription and 100,000 users from the EU, you will end up with an array of 200,000 user records loaded in memory. That’s clearly a problem and can cause your request to fail because it runs out of memory.
Second solution: pluck the IDs
Instead, you can go for a more efficient solution.
users_with_a_subscription = User.where(is_subscribed: true)
users_from_the_eu = User.where(region: 'eu')
result = User.where(
id: users_with_a_subscription.pluck(:id) + users_from_the_eu.pluck(:id)
)
This is better! You now perform three queries instead of two but the first two
are a bit more efficient as you only fetch the id column of the users table
instead of users.*.
More importantly, you avoid having to load tons of data in memory. Sure, you still have to construct an array of 200,000 elements but this time they are simply integers (or fixed-length strings if your primary key is a UUID) instead of ActiveRecord records. From Sutori:
# 120 bytes
ObjectSpace.memsize_of(User.first)
# it returns 0 bytes but I suspect it's 4 bytes as it corresponds to
# 32-bit precision.
ObjectSpace.memsize_of(1053252353262364364)
This solution has one other problem though: you quickly fill up Rails’ cache of prepared statements. A prepared statement is the compiled version of an SQL query after it’s been parsed and analyzed. It’s faster to execute the prepared statement of a query because these steps don’t need to be performed.
For this reason, Rails maintains a cache that contains up to 1000 prepared statements. Every time your application executes a different query, its prepared statement is added to the cache. This means that if you have more than 1000 different queries in your application, some prepared statements will have to be evicted from the cache, resulting in a slight performance degradation.
The problem with the solution above is that it generates a new query for each combination of IDs. So it drastically increases the likelihood of filling up the cache of prepared statements, thereby degrading the performance.
Third solution: use or
So what is best solution? I recommend using the
[or](https://api.rubyonrails.org/v5.2.0/classes/ActiveRecord/QueryMethods.html#method-i-or)
method that was introduced in Rails 5. It’s very simple.
users_with_a_subscription = User.where(is_subscribed: true)
users_from_the_eu = User.where(region: 'eu')
result = users_with_a_subscription.or(users_from_the_eu)
Here’s why this is better:
- It executes a single query. While it’s more complex than in previous solutions, one complex query is still faster than multiple simple queries.
- It generates a single prepared statement. We are not interpolating any IDs in the query so every time we run the query, we are executing the same one.
What about single-page applications?
As far as I know, all the applications studied in the paper are “traditional” Rails applications, i.e. the HTML is generated by the backend. However, Sutori is a single-page application and its Rails backend exposes a JSON-only API. This makes me wonder, do JSON APIs suffer from the same issues that the authors have identified?
Unfortunately, this seems to be the case. I think that generating JSON is overall more performant than generating HTML, mostly because the server doesn’t need to execute business logic that you find in HTML views. Instead, this logic is executed in the client’s browser for single-page applications. However, the performance issues stemming from the usage of the ORM framework do not magically disappear when you output JSON instead of HTML.
Fixing the issues
After having identified all these performance problems from the 12 studied applications, the authors continued their endeavour and manually fixed the issues. Their intent was two-fold: to measure the impact of their fixes on the performance and to observe the complexity of their implementation.
The most striking thing that came out of this was that 78% of all fixes required fewer than 5 lines. This surely means that the fixes are not so complex that they need hundreds of lines of code. However, it’s slightly misleading because the hard part is of course finding the right 5 lines of code that fix the issue.
For instance, I can give you the following implementation of quicksort in Haskell:
qsort (p:xs) = qsort [x | x<-xs, x<p] ++ [p] ++ qsort [x | x<-xs, x>=p]
Simple, right? It’s only one line of code! However, there are so many concepts packed into this one line of code. Someone who doesn’t know about list comprehensions for example will have a hard time understanding this piece of code, let alone come up with it himself.
This also applies to the ActiveRecord-related performance fixes. Someone who
doesn’t know that map and pluck result in different SQL queries will have a
hard time fixing the issue. Therefore, statements like “fewer lines of
code is simpler” should be taken with some reservation.
Bringing the discussion to Sutori
The question now becomes, “are there things we can do to prevent these issues?” At Sutori, we have tried to address this over the years, and in the following sections I’ll give an overview of how we prevent, monitor and fix performance problems at Sutori.
Types of performance issues we encounter
I would say that most of the issues raised by the paper can be prevented by gaining more experience with the ActiveRecord API. ActiveRecord is a (sometimes ugly) beast with many quirks. But once you’re aware of them, you will be able to identify the situations where you should careful of how to write things.
For this reason, most of our performance bottlenecks come from only two problems:
- Serialization to JSON. This is unrelated to ORMs but we are seeing issues due to active_model_serializers being very slow. We hope to replace it with fast_jsonapi soon. Note that we can easily substitute JSON serialization gems thanks to the JSON API standard!
- N+1 queries. These just keep re-appearing. I think that the reason they are so hard to detect is their non-local nature. The way you render HTML or JSON determines how you should write your query in your controller or service object. So the logic in one file directly affects the query you should write in another file. That makes N+1 queries hard to reason about and likely to go unnoticed during a code review.
Prevention is better than cure
How do we limit the occurrences of N+1 queries? By integrating the bullet gem into our test suite. Bullet is a great piece of software that can detect N+1 queries at run-time.
When we run a request spec for any endpoint, Bullet automatically runs along with the test. It raises an error when it detects an N+1 query, which causes the test to fail. This allows us to detect some N+1 queries early on, on the developer’s computer or on CI.
Assuming that you use RSpec, you can set this up by adding the following
snippet to the RSpec configuration in spec/rails_helper.rb:
# spec/rails_helper.rb
config.around(:each, type: 'request') do |example|
unless example.metadata[:bullet] == false
Bullet.enable = true
Bullet.raise = true
end
example.run
Bullet.enable = false
end
This has helped us more than once in preventing an N+1 query from creeping into production code. However, it’s not a perfect solution, as its effectiveness depends a lot on how you set up the records in your spec. After all, you need to create sufficient records in your spec for N+1 queries to manifest themselves. Either way, something is better than nothing.
Monitoring
Performance monitoring is a must. We’ve found Scout to be a very good yet affordable service. Its most useful features are the N+1-query detection and the memory bloat insights. The most problematic traces appear at the top, allowing you to focus your attention on the most pressing issues first. Furthermore, it tells you the exact query parameters for the trace so you can perfectly reproduce the request.
Fixing the problems
An N+1 query slipped through the net of our test suite and has shown up in Scout. The procedure to resolve it is as follows:
- Reproduce the request locally.
- Extend the request spec of the endpoint so that Bullet raises an error.
- Fix the issue.
Remote debug database
How do you reproduce the request locally, with production data? For that, we have a remote debug database that contains a copy of the production database. Every night, we run a script that reads a backup of the production database and imports it into the debug database.
We then set up a DEBUG environment that connects to this remote database
instead of the local database. So running the app with production data is as
easy as running:
$ RAILS_ENV=debug rails s
Naturally, this drastically degrades the performance of the application as a simple 1ms query to the local database now requires a round-trip to an AWS data center and takes more like 50ms instead. However, what matters in solving an N+1 query is the number of queries that are executed rather than their timings.
To gain insight in the SQL query count, we use the Developer Mode of the New Relic gem. This is available in the free plan of New Relic. Unfortunately, New Relic has removed this functionality in their latest version of the gem so we’re forced to stay on the older 4.x. Scout is working on something similar but it hasn’t come out yet.
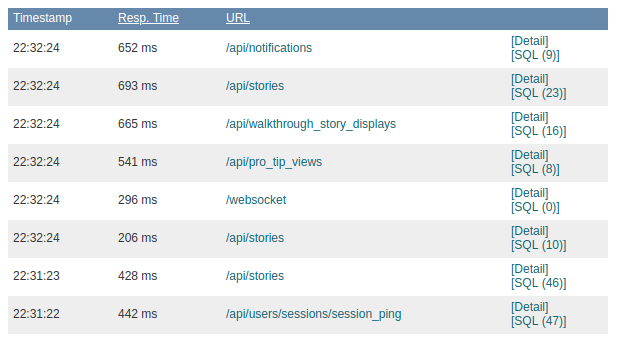
You can see the number of SQL queries per request in New Relic Developer Mode.
In the details of a request in New Relic Developer Mode, you can see the exact queries and the stacktrace from the line in your application that triggered them. Armed with this information, you can fix the issue and have direct feedback on whether it’s a right fix or not.
How to go from here
We’re doing the best we can with the tools at our disposals to prevent ORM-related performance issues from occurring. However, I do think we can improve the situation.
Clean up the ActiveRecord API
A lot of the issues come from the fact that the ActiveRecord API is very messy
and inconsistent at times. For example, size, length and count are
functionally all equivalent in that they retrieve the number of elements in a
set of records. However, their implementation and therefore performance
characteristics are very different. Cleaning up the ActiveRecord API, within
the limits imposed by backwards compatibility, could be a start.
Better tooling
Ultimately, the development of tooling such as bullet will have the biggest impact.
Static analysis
The holy grail is, of course, static analysis. While I don’t know enough about the topic to have an opinion on its feasibility, I can only imagine it as being too hard, or even maybe impossible, to have strong static analysis tools that can detect ORM-related performance issues for a language as dynamic as Ruby.
Run-time assistance
Another option is to have assistance at run-time. For instance, there could be a
check inside the map method of ActiveRecord that would detect whether you’re
trying to map a database column. It could then output a warning advising you to
use pluck instead of map. In that warning it could direct you to a page of
the Rails guide explaining its rationale, thereby educating the developer. Such
checks would only run in the development and test environments so that it avoids
a performance penalty in production. I think that such a system is technically
feasible.
Conclusion
The article helped me to understand the common performance problems that arise from using an ORM such as ActiveRecord. I’ve found this very relatable to the work that I do on Sutori. I hope that the experiences that I shared are helpful to some readers. Furthermore, I am optimistic that better tooling will be built to help us, developers, avoid these common pitfalls.